Java复习Day3 学到的接口:
常见API学习
Object类 1.toString() 引用类型变量未重写则打印的是地址而非内容,需要重写toString方法
2.equals() 1.s1==s2不管是否重写equals(),始终比较的是二者的地址
3.clone() 要克隆某个类,首先让该类实现Cloneable这一标记接口(空接口),然后重写其clone方法
直接生成的是浅克隆
自己手写深克隆
Objects类 包装类 为了实现万物皆对象,把基本类型的变量改为对象
自动装箱与自动拆箱机制
Integer->String
String->Integer
String 开始之前的注意:
String
StringBuilder StringBuilder s=new StringBuilder();
StringBuffer 用法和StringBuilder差不多就不说了
StringJoiner StringJoiner sJ=new StringJoiner(“,”,”[“,”]”);//间隔符,开头,结尾
Math
System System.exit(0);//非0是异常退出,人为退出虚拟机不要使用
其他获取系统的时间(指的是从1970-1-1至今的毫秒总数)的方法
Runtime Runtime r=Runtime.getRuntime();//返回与当前Java程序关联的运行时对象
BigDecimal BigDecimal写法用于解决浮点数运算结果失真的情况,要求得到具体值包装类Double->BigDecimal
BigDecimal->包装类Double
利用BigDecimal实现四则运算
内部类 成员内部类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class outer{ private int age=6;//----->outer.inner.age public class inner{ private int age=3;//----->this.age public void printAge(){ int age=8;//----->age System.out.println(age);//8 System.out.println(this.age);//3 System.out.println(outer.this.age);//6 } } public static void main(String[] args) { outer.inner lei=new outer().new inner(); lei.printAge(); } } outer.inner in=new Outer().new inner();
静态内部类 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class outer2{ private int age=6;//----->outer.inner.age public static class inner{ private int age=3;//----->this.age public void printAge(){ int age=8;//----->age System.out.println(age);//8 System.out.println(this.age);//3 //System.out.println(outer2.this.age);//报错 } } public static void main(String[] args) { outer2.inner lei=new outer2. inner(); lei.printAge(); } } outer.inner in=new Outer.inner();
匿名内部类 之前学接口实现类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 interface swimming{ void swim(); } class A implements swimming{ @Override public void swim() { System.out.println("A游得快"); } } public class outer3 { public void swimFast(swimming sm){ sm.swim(); } public static void main(String[] args) { outer3 outer3=new outer3(); swimming s=new A();//注意平时若使用多态写法不能使用子类独有功能与方法 outer3.swimFast(s); } }
现在使用匿名内部类,可以少创建一个实现类,main函数可写为
1 2 3 4 5 6 7 8 9 10 public static void main(String[] args) { outer3 outer3=new outer3(); swimming s2=new swimming() { @Override public void swim() { System.out.println("B游得快"); } }; outer3.swimFast(s2); }
可进一步简化为
1 2 3 4 5 6 7 8 9 10 public static void main(String[] args) { outer3 outer3=new outer3(); outer3.swimFast(new swimming() { @Override public void swim() { System.out.println("C游得快"); } }); ///学完Lambda表达式后可进一步简化为:outer3.swimFast(() -> System.out.println("C游得快")); }
Arrays类 int arr[]=new int[]{11,22,33};
//1.返回数组的内容
System.out.println(Arrays.toString(arr));
//2.原数组扩容,新增位默认为0
int a2[]=Arrays.copyOf(arr,8);
System.out.println(Arrays.toString(a2));
//3.拷贝数组,左闭右开
int a3[]=Arrays.copyOfRange(arr,0,2);
System.out.println(Arrays.toString(a3));
//4.setAll把原数据改为新数据又存进去
double prices[]=new double[]{25.0,17.0,36.0};
Arrays.setAll(prices, new IntToDoubleFunction() {//接口作为参数传入,匿名内部类
@Override
public double applyAsDouble(int value) {
BigDecimal price=BigDecimal.valueOf(prices[value]).multiply(BigDecimal.valueOf(0.8));
return price.doubleValue();//把BigDemical转换为double类
}
});
//用Lambda表达式简化
Arrays.setAll(prices, value -> prices[value]*0.8 ); //继续简化
//5.排序
当排序的对象为自定义类
Student[]student=new Student[]{new Student(17, "大明", 180.0),new Student(20, "小红", 165.0),new Student(19, "小刚", 170.0)};
时,有以下两种处理法
1.让对象的类实现Comparable接口
(implements Comparable<Student>)
,然后重写compareTo接口(写在Student类里面的),自定义排序规则(依照对象的什么参数进行排序)
( @Override
public int compareTo(Student o) {
return this.age-o.age;//升序
//return o.age-this.age;//降序
}//默认:左小于右,返回负数,左大于右,返回正数,左等于右,返回零,故为升序结果)
Arrays.sort(students);
System.out.println(Arrays.toString(students));
System.out.println("-------");
2.改写Arrays.sort()方法,调用Comparator比较器
Arrays.sort(students, new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
//return (int)(o1.getHeight()-o2.getHeight());//这样写会有问题,17.1-17.0他会认为是0,也就是二者相等
return Double.compare(o1.getHeight(),o2.getHeight());//升序
//return Double.compare(o2.getHeight(),o1.getHeight());//降序
}
});
Lambda表达式 Lambda表达式
1)作用:简化匿名内部类的代码
2)使用前提:只能简化函数式接口的匿名内部类
格式(被重写方法的形参列表)->{被重写方法的方法体代码}
注:1.函数式接口(有且仅有一个抽象方法的接口)
2.函数式接口大多存在一个为@Functionalinterface的注解
3)进一步简化(见ArraY类)
1.参数类型可以不写
2.如果只有一个参数,参数类型可以忽略,同时()也可以省略
3.如果Lambda表达式中方法体代码只是一行代码,可以省略大括号不写,同时省略分号,若为return语句,也必须去掉return语句
简化过程:() {
Lambda表达式在JDK8后的新特性–方法引用
静态方法 若表达式只是引用一个static方法,且前后参数形式一致,就可使用静态方法引用类::static方法
实例方法 若表达式只是引用一个实例方法,且前后参数形式一致,就可使用静态方法引用对象::实例方法
特殊类型方法只是引用一个实例方法,且参数列表第一个参数作为方法的主调 ,后面的参数都是作为这个实例方法的入参的,此时可以作为特定类型的方法引用T(泛型)::方法名 () {
step2 Arrays.sort(names, (String o1, String o2)->o1.compareToIgnoreCase(o2));() {只是在创建对象,且前后参数情况一致 ,就可以使用构造器引用类名::new
时间 旧时间
Date 1 2 3 4 5 6 7 8 9 10 11 两种构造器 Date(); Date(long time); 常见方法 public void setTime(long time) { fastTime = time; cdate = null; } public long getTime() { return getTimeImpl(); }
1 2 3 4 5 6 7 8 9 10 11 Date date=new Date();//构造器1 System.out.println(date);//在2024//11/25 21:01运行得到 Mon Nov 25 21:01:00 CST 2024 long time=date.getTime(); System.out.println(time);//返回自1970.1.1至今走过的时间毫秒 time+=7*1000; Date date1=new Date(time);//构造器2 System.out.println(date1);//得到7秒后的时间 System.out.println("----------"); System.out.println(date);//像别人写好的自定义类都重写了toString()这些 date.setTime(time); System.out.println(date);//让date的时间变为变化后的而非一早的
SimpleDateFormat 1 2 3 4 5 6 7 8 继承关系: public class SimpleDateFormat extends DateFormat 常见构造器: SimpleDateFormat()//使用默认 FORMAT 区域设置的默认模式和日期格式符号构造 SimpleDateFormat SimpleDateFormat(String pattern)//使用给定的模式和默认 FORMAT locale的默认日期格式符号构造一个 SimpleDateFormat 方法: 1.格式化时间对象(时间->字符串) 2.解析字符串中的时间为日期对象(字符串->时间)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public static void main(String[] args) throws ParseException { Date date=new Date(); long time=date.getTime(); //1.格式化时间对象(时间->字符串) SimpleDateFormat sdf= new SimpleDateFormat("YYYY年MM月dd日 HH:mm:ss EEE a"); //2024年11月25日 21:28:22 星期一 String rs1=sdf.format(date); String rs2=sdf.format(time); System.out.println(rs1); System.out.println(rs2);//两行打印出来是一样的 System.out.println("---------"); //2.解析字符串中的时间为日期对象(字符串->时间) String rs3="2024-11-25 21:31:00"; SimpleDateFormat sdf2=new SimpleDateFormat("YYYY-MM-dd HH:mm:ss"); Date date2=sdf2.parse(rs3);//上面两行格式要一致,否则抛异常 System.out.println(date2); }
calendar {};1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public static void main(String[] args) { Calendar ca=Calendar.getInstance();//获取当前日历对象 System.out.println(ca);//Shanghai指的是上海时区 int year=ca.get(Calendar.YEAR);//获取日历的某个信息 System.out.println(year); int days=ca.get(Calendar.DATE); System.out.println(days); int day=ca.get(Calendar.DAY_OF_YEAR); System.out.println(day);//这一年的第多少天 Date date=ca.getTime();//日期对象 System.out.println(date); long time=ca.getTimeInMillis();//毫秒值 System.out.println(time); //变化一些值 ca.set(Calendar.MONTH,9);//他是从0开始记录的,此时是修改成了10月份,输出里面还是MONTH=9 System.out.println(ca); ca.add(Calendar.DAY_OF_YEAR,100); ca.add(Calendar.DAY_OF_MONTH,1); ca.add(Calendar.HOUR,4); System.out.println(ca); } //注:它的对象为可变对象,修改后原先存储的内容数据就会消失
JDK8开始的新时间 搞清楚为什么要用JDK 8开始新增的时间类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class Test { public static void main(String[] args) { // 传统的时间类(Date、SimpleDateFormat、Calendar)存在如下问题: // 1、设计不合理,使用不方便,很多都被淘汰了。 Date d = new Date(); //System.out.println(d.getYear() + 1900); Calendar c = Calendar.getInstance(); int year = c.get(Calendar.YEAR); System.out.println(year); // 2、都是可变对象,修改后会丢失最开始的时间信息。 // 3、线程不安全。 // 4、不能精确到纳秒,只能精确到毫秒。 // 1秒 = 1000毫秒 // 1毫秒 = 1000微妙 // 1微妙 = 1000纳秒 } }
新时间学习路线
Step1 代替Calendar1Date 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 public class InsteadCalendar1Date { public static void main(String[] args) { //LocalDate获取对象法一 LocalDate ld=LocalDate.now();//代表本地日期(年、月、日、星期),是不可变对象 LocalDate ldof = LocalDate.of(2026,6,7); /* 方法名 说明 public int geYear() 获取年 public int getMonthValue() 获取月份(1-12) public int getDayOfMonth() 获取日 public int getDayOfYear() 获取当前是一年中的第几天 Public DayOfWeek getDayOfWeek() 获取星期几:ld.getDayOfWeek().getValue() 方法名 说明 withYear、withMonth、withDayOfMonth、withDayOfYear 直接修改某个信息,返回新日期对象 plusYears、plusMonths、plusDays、plusWeeks 把某个信息加多少,返回新日期对象 minusYears、minusMonths、minusDays,minusWeeks 把某个信息减多少,返回新日期对象 equals isBefore isAfter 判断两个日期对象,是否相等,在前还是在后 */ System.out.println(ldof);//2026-06-07 System.out.println(ld);//2025-02-06 System.out.println(ld.getYear());//2025 System.out.println(ld.getMonthValue());//2 System.out.println(ld.getDayOfMonth());//6 System.out.println(ld.getDayOfYear());//37 System.out.println(ld.getDayOfWeek().getValue());//4 LocalDate ld2 = ld.withYear(2036); System.out.println(ld2);//2036-02-06 System.out.println(ld.plusMonths(2).isBefore(ld2));//确实在前面,返回true } } public class InsteadCalendar2Time { public static void main(String[] args) { LocalTime lt=LocalTime.now();//代表本地时间(时、分、秒、纳秒),是不可变对象 LocalTime ltof = LocalTime.of(7, 3,2,7000000); System.out.println(ltof);//07:03:02.007 System.out.println(lt);//23:14:43.989 System.out.println(lt.getHour());//23 System.out.println(lt.getMinute());//14 System.out.println(lt.getSecond());//43 System.out.println(lt.getNano());//989000000 //修改with,加plus,减minus,判断相等在前在后也一样 } } public class InsteadCalendar3DateTime { //也是两种获取对象的方法,其他方法也大差不差,就多了个转化 public static void main(String[] args) { LocalDateTime ldt=LocalDateTime.now();//代表本地日期、时间(年、月、日、星期、时、分、秒、纳秒),是不可变对象 LocalDateTime ldtof = LocalDateTime.of(ldt.toLocalDate(), ldt.toLocalTime()); System.out.println(ldtof);//2025-02-06T23:19:08.448 //LocalDateTime的转换成LocalDate、LocalTime System.out.println(ldt);//2025-02-06T23:19:08.448 System.out.println(ldt.toLocalDate());//2025-02-06 System.out.println(ldt.toLocalTime());//23:19:08.448 } } public class InsteadCalendar4ZoneIdZonedDateTime { public static void main(String[] args) { //ZoneId //法一 默认时区 ZoneId zi=ZoneId.systemDefault(); System.out.println(zi);//Asia/Shanghai 输出一致是因为它的toString方法调用了getId(); System.out.println(zi.getId());//Asia/Shanghai //法二 所有时区 System.out.println(ZoneId.getAvailableZoneIds()); //ZoneId.getAvailableZoneIds().forEach( s->System.out.print(s+" ")); //法三 指定时区 ZoneId zof = ZoneId.of("America/Marigot"); System.out.println(zof);//America/Marigot System.out.println("-------"); //ZonedDateTime System.out.println(ZonedDateTime.now(Clock.systemUTC()));//获取的是标准时间2025-02-06T15:42:01.556Z System.out.println(ZonedDateTime.now());//获取的是系统默认时区的时间 ZonedDateTime zd1 = ZonedDateTime.now(ZoneId.of("Africa/Cairo")); //后面的和LocalDateTime大差不差 System.out.println(zd1);//2025-02-06T17:42:01.553+02:00[Africa/Cairo] System.out.println(zd1.getHour());//17 System.out.println(zd1.plusMonths(7));//2025-09-06T17:42:01.553+03:00[Africa/Cairo] //补充:Calendar中也可使用时区,但使用之后会变化,而且API也不好用 //Calendar instance = Calendar.getInstance(TimeZone.getTimeZone(zof)); } }
Step2 代替Date 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public class InsteadDate { public static void main(String[] args) { Instant is = Instant.now(); int nano = is.getNano();//从时间线开始,获取从第二个开始的纳秒数 long epochSecond = is.getEpochSecond();//获取从1970-01-01T00:00:00开始记录的秒数。 System.out.println(is); System.out.println(epochSecond); System.out.println(nano); System.out.println(is.plusNanos(1000)); System.out.println(is.equals(Instant.now())); System.out.println(nano);//前后不变 //用途:可以用来记录代码的执行时间,或用于记录用户操作某个事件的时间点。 Instant is2=Instant.now(); //...程序 Instant is3=Instant.now(); /* 传统的Date类,只能精确到毫秒,并且是可变对象; 新增的Instant类,可以精确到纳秒,并且是不可变对象,推荐用Instant代替Date。 */ } }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class InsteadSimpleDateFormat { public static void main(String[] args) { //避免线程不安全 DateTimeFormatter dateTimeFormatter = DateTimeFormatter.ofPattern("yyyy年MM年dd日 HH:mm:ss");//时间格式化器 System.out.println(dateTimeFormatter.format(ZonedDateTime.now(ZoneId.systemDefault())));// System.out.println(dateTimeFormatter.format(LocalDateTime.now())); //LocalDateTime提供的格式化、解析时间的方法 System.out.println(LocalDateTime.now().format(dateTimeFormatter)); //解析 String rs="2025年02年07日 20:34:13"; System.out.println(LocalDateTime.parse(rs,dateTimeFormatter)); } }
Step4 补充:Period,Duration 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class MorePeriod { public static void main(String[] args) { //可以用于计算两个 LocalDate对象 相差的年数、月数、天数 LocalDate start = LocalDate.now(); LocalDate end = LocalDate.of(2025, 7, 6); Period between = Period.between(start, end); System.out.println(between.getYears());//0 System.out.println(between.getMonths());//4 System.out.println(between.getDays());//29 是相减后剩下不足一月的天数 } } public class MoreDuration { //可以用于计算两个时间对象相差的天数、小时数、分数、秒数、纳秒数;支持LocalTime、LocalDateTime、Instant public static void main(String[] args) { LocalTime start =LocalTime.now(); LocalTime end = LocalTime.of(22, 49, 56); Instant now = Instant.now(); Instant instant = now.plusMillis(1000000); Duration d=Duration.between(now,instant); System.out.println(d.toMinutes()); Duration between = Duration.between(start, end); System.out.println(between.toDays()); System.out.println(between.toHours()); System.out.println(between.toMinutes()); System.out.println(between.toMillis());//计算隔多少毫秒,并返回 System.out.println(between.toNanos());//计算隔多少纳秒,并返回 } }
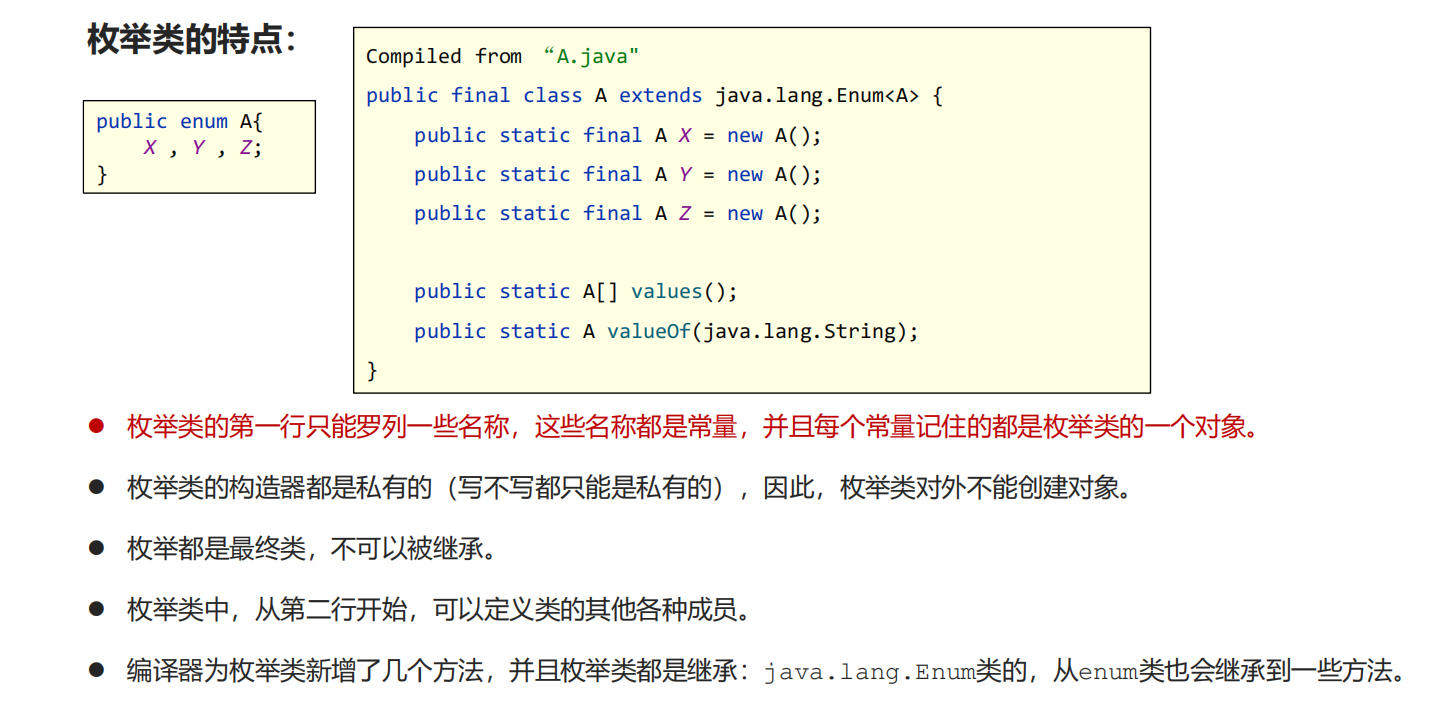
枚举 注:
javac java
.java——->.class——>送到虚拟机运行(+核心类库)
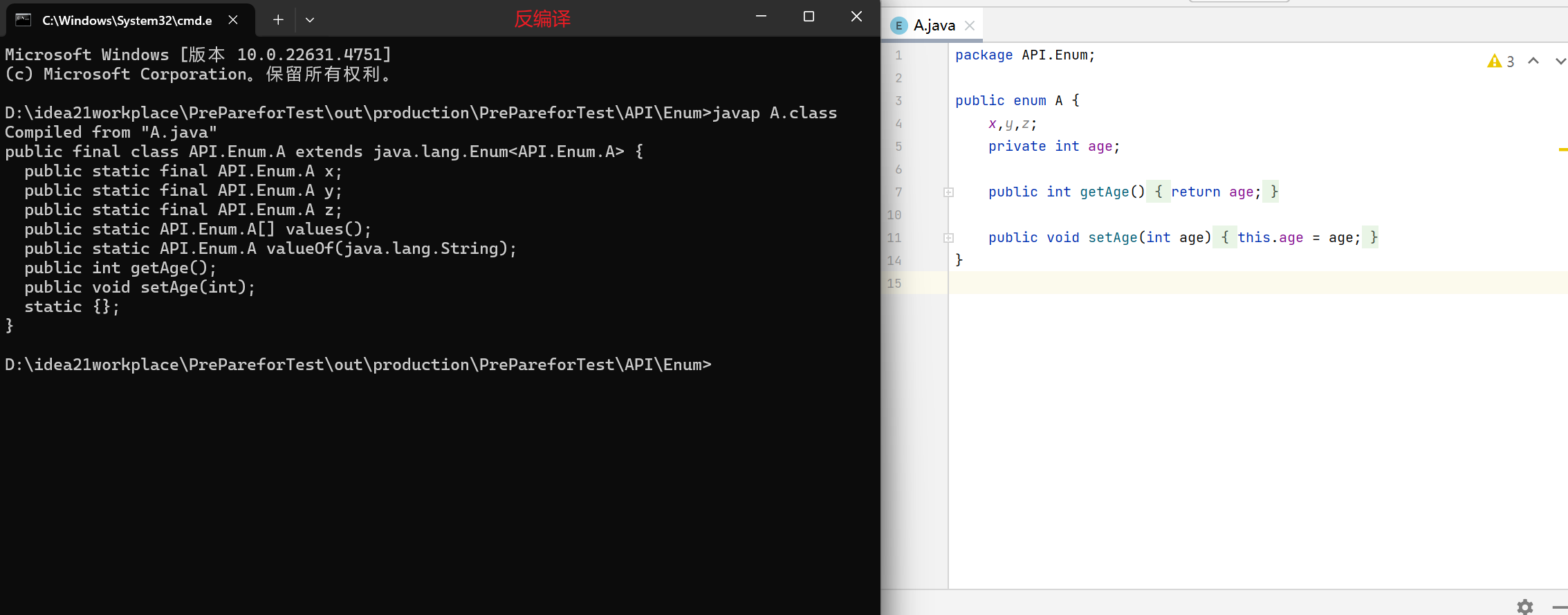
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 public enum A { x,y,z;//枚举类的第一行只能罗列一些名称,这些名称都是常量, // 并且每个常量记住的都是枚举类的一个对象。 private int age; A() { } A(int age) { this.age = age; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } } //补充:抽象枚举 public enum B {//和一般类不一样此处不加abstract //x;//抽象类不能直接创建对象,子类继承多态或者匿名内部类 x() { @Override public void go() { } },y("张三") { @Override public void go() { System.out.println(getName()+"在走"); } }; B() { } B(String name) { this.name = name; } public String getName() { return name; } public void setName(String name) { this.name = name; } private String name; public abstract void go();//抽象方法没有方法体 } public class Test { public static void main(String[] args) { //不能创建对象 //A a1=new A(); A a=A.x; a.setAge(8); System.out.println(a.getAge());//8 System.out.println(a);//x A[]b=A.values();//获取所有 System.out.println(Arrays.toString(b));//[x, y, z] A c=A.valueOf("z");//根据字符找常量 System.out.println(c.name());//z System.out.println(c.ordinal());//返回索引2 System.out.println("---------"); B d=B.y; System.out.println(d);//y d.go();//张三在走 } }
1 2 3 4 //多学一招:用枚举实现单例设计模式 public enum C { x; }
枚举的应用场景
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public enum Sex { x,y; } public class AppEnum { public static void main(String[] args) { Sex a=Sex.x; check(a); } public static void check(Sex sex){ switch (sex){ case x://在 Java 中,当使用 switch 语句处理枚举类型时, // case 标签必须使用枚举常量的未限定名称。这意味着你不应该在枚举常量前加上枚举类型的名称 System.out.println("nba球星"); break; case y: System.out.println("女明星"); break; default: break; } } }
泛型 定义类、接口、方法时,同时声明了一个或者多个类型变量如:<**E**> ,称为泛型类、泛型接口,泛型方法、它们统称为
泛型类 修饰符 class 类名<类型变量,类型变量,…>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 //泛型类 public class MyArrayList<E>{ Object[]obj=new Object[10]; private int size; public MyArrayList() { this.size = 0; } public int getSize() { return size; } public void setSize(int size) { this.size = size; } public boolean add(E e){ if(this.size>=obj.length){ obj=Arrays.copyOf(obj,size*2); } obj[size] = e; size++; return true; } public E getE(int index){ if(index>=0&&index < size) { return (E)obj[index]; } return null; }; } public class MyClass2<E,T> { public void put(E e,T t){ } public MyClass2(){ } } public class MyClass3<E extends Animal> { } public class MyClass4 <Animal>{//错误写法,并非是 // 要求必须是Animal类了,而是把它当作E,继承Object类了 // 参数可以随便写,应按照MyClass3那样写 } public class Animal { } public class Dog extends Animal{ } public class Test { public static void main(String[] args) { MyArrayList list2=new MyArrayList();//若不使用泛型都是object类型 MyArrayList<String>list=new MyArrayList<>(); list.add("7"); list.add("8"); System.out.println(list.getE(0)); MyClass2<Animal,String>my2=new MyClass2<>(); //MyClass3<String>wrong=new MyClass3<>();//会报错,泛型类型不是animal或其子类 MyClass3<Animal>m3=new MyClass3<>(); MyClass3<Dog>m33=new MyClass3<>(); MyClass4<String>m4=new MyClass4<>();//不报错,参数随便写,因为泛型都搞错了 } }
泛型接口 修饰符 interface 接口名<类型变量,类型变
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 // 目标:掌握泛型接口的定义和使用。 // 场景:系统需要处理学生和老师的数据,需要提供2个功能:保存对象数据。根据名称查询数据。 public interface Data <E >{ void add(E e); ArrayList<E> getByName(E e); } public class StudentData implements Data<Student>{ @Override public void add(Student student) { } @Override public ArrayList<Student> getByName(Student student) { return null; } } public class TeacherData implements Data<Teacher>{ @Override public void add(Teacher teacher) { } @Override public ArrayList<Teacher> getByName(Teacher teacher) { return null; } } public class Student { } public class Teacher { }
泛型方法、泛型通配符、上下限 自己定义泛型变量的才是泛型方法,哪怕是用的自己所在泛型类所给的类型的都不算泛型方法,比如
1 2 3 4 5 6 7 8 public class MyArrayList<E>{ ...... public E getE(int index){ if(index>=0&&index < size) { return (E)obj[index]; } return null; }
就不算泛型方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 public class Dog { private String name; public Dog() { } public Dog(String name) { this.name = name; } public String getName() { return name; } public void setName(String name) { this.name = name; } @Override public String toString() { return "狗的名字是"+this.getName(); } } /* 修饰符 (static)<类型变量,类型变量,…> 返回值类型 方法名(形参列 表) { } */ public class Test1 { public static void main(String[] args) { test1(); System.out.println(test2(3));//3 System.out.println(test3(8));//8 System.out.println(test3("java"));//java System.out.println(test3(new Dog("哈哈哈")));//狗的名字是哈哈哈 } public static <N> void test1(){ }//泛型无意义 public static <N> int test2(int c){ return c; }//泛型无意义 public static <N> N test3(N n){ return n; } }
例二
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 public class Car { } class BENZ extends Car{ } class BMW extends Car{ } public class Test2 { public static void main(String[] args) { ArrayList<BENZ>benCars=new ArrayList<>(); ArrayList<BMW>bmwCars=new ArrayList<>(); //go(benCars);会报错!只是方法的参数是泛型类对象<Car>的子类 go1(benCars); go1(bmwCars); go1(new ArrayList<Dog>());//也不报错,所以要限制E go2(new BENZ()); go2(new BMW());//不报错,就是多态写法,与go要区分开! go3(benCars); go3(bmwCars); go3(new ArrayList<Car>()); //go3(new ArrayList<Dog>());//报错了 /* Required type:ArrayList<E> Provided:ArrayList<Dog> */ go4(new ArrayList<Dog>());//不报错 //go5(new ArrayList<Dog>());//会报错了 } public static void go(ArrayList<Car> car){//点名道姓了参数具体要求,子类当然不行了 } public static<E> void go1(ArrayList<E> cars){ } public static void go2(Car cars){ } public static<E extends Car> void go3(ArrayList<E> cars){ } /* 使用通配符简化 */ public static<E extends Car> void go4(ArrayList<?> cars){ }//可以在“使用泛型”的时候代表一切类型 public static<E extends Car> void go5(ArrayList<? extends Car> cars){ }//泛型上限: ? extends Car: ? 能接收的必须是Car或者其子类 。 public static<E extends Car> void go6(ArrayList< ? super Car> cars){ }//泛型下限: ? super Car : ? 能接收的必须是Car或者其父类。 }
泛型的注意事项:擦除问题、基本数据类型问题 泛型的擦除问题和注意事项
正则表达式 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 public class RegexTest2 { public static void main(String[] args) { // 1、字符类(只能匹配单个字符) System.out.println("a".matches("[abc]")); // [abc]只能匹配a、b、c System.out.println("e".matches("[abcd]")); // false System.out.println("d".matches("[^abc]")); // [^abc] 不能是abc System.out.println("a".matches("[^abc]")); // false System.out.println("b".matches("[a-zA-Z]")); // [a-zA-Z] 只能是a-z A-Z的字符 System.out.println("2".matches("[a-zA-Z]")); // false System.out.println("k".matches("[a-z&&[^bc]]")); // : a到z,除了b和c System.out.println("b".matches("[a-z&&[^bc]]")); // false System.out.println("ab".matches("[a-zA-Z0-9]")); // false 注意:以上带 [内容] 的规则都只能用于匹配单个字符 System.out.println("-------------"); // 2、预定义字符(只能匹配单个字符) . \d \D \s \S \w \W System.out.println("徐".matches(".")); // .可以匹配任意字符 System.out.println("徐徐".matches(".")); // false // \转义 System.out.println("\""); // \n \t System.out.println("3".matches("\\d")); // \d: 0-9 System.out.println("a".matches("\\d")); //false System.out.println(" ".matches("\\s")); // \s: 代表一个空白字符 //System.out.println("a".matches("\s")); // false System.out.println("a".matches("\\S")); // \S: 代表一个非空白字符 System.out.println(" ".matches("\\S")); // false System.out.println("a".matches("\\w")); // \w: [a-zA-Z_0-9] System.out.println("_".matches("\\w")); // true System.out.println("徐".matches("\\w")); // false System.out.println("徐".matches("\\W")); // [^\w]不能是a-zA-Z_0-9 System.out.println("a".matches("\\W")); // false System.out.println("23232".matches("\\d")); // false 注意:以上预定义字符都只能匹配单个字符。 // 3、数量词: ? * + {n} {n, } {n, m} System.out.println("a".matches("\\w?")); // ? 代表0次或1次 System.out.println("".matches("\\w?")); // true System.out.println("abc".matches("\\w?")); // false System.out.println("abc12".matches("\\w*")); // * 代表0次或多次 System.out.println("".matches("\\w*")); // true System.out.println("abc12张".matches("\\w*")); // false System.out.println("abc12".matches("\\w+")); // + 代表1次或多次 System.out.println("".matches("\\w+")); // false System.out.println("abc12张".matches("\\w+")); // false System.out.println("a3c".matches("\\w{3}")); // {3} 代表要正好是n次 System.out.println("abcd".matches("\\w{3}")); // false System.out.println("abcd".matches("\\w{3,}")); // {3,} 代表是>=3次 System.out.println("ab".matches("\\w{3,}")); // false System.out.println("abcde徐".matches("\\w{3,}")); // false System.out.println("abc232d".matches("\\w{3,9}")); // {3, 9} 代表是 大于等于3次,小于等于9次 // 4、其他几个常用的符号:(?i)忽略大小写 、 或:| 、 分组:() System.out.println("abc".matches("(?i)abc")); // true System.out.println("ABC".matches("(?i)abc")); // true System.out.println("aBc".matches("a((?i)b)c")); // true System.out.println("ABc".matches("a((?i)b)c")); // false // 需求1:要求要么是3个小写字母,要么是3个数字。 System.out.println("abc".matches("[a-z]{3}|\\d{3}")); // true System.out.println("ABC".matches("[a-z]{3}|\\d{3}")); // false System.out.println("123".matches("[a-z]{3}|\\d{3}")); // true System.out.println("A12".matches("[a-z]{3}|\\d{3}")); // false // 需求2:必须是”我爱“开头,中间可以是至少一个”编程“,最后至少是1个”666“ System.out.println("我爱编程编程666666".matches("我爱(编程)+(666)+")); System.out.println("我爱编程编程66666".matches("我爱(编程)+(666)+")); } }
集合
Collection
常用方法1 2 3 4 5 6 7 8 Collection<String>k1=new ArrayList(); Collection<String>k2=new ArrayList(); k1.add("666"); k2.add("777"); Object[] objects = k1.toArray();//无参 String[] strings = k1.toArray(new String[k1.size()]);//有参,全是同种类型的元素 k1.addAll(k2);//相当于是拷贝一份过来(全倒进来) System.out.println(k1);//666,777
遍历1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 //方法一 迭代器 Iterator<String> iterator = k1.iterator(); while (iterator.hasNext()) {//询问当前位置是否存在元素 System.out.println(iterator.next());//取当前位置元素,然后后移一位 //问一次取一次,不要每次问完取多次 } System.out.println("-------------"); //方法二 增强for(本质上还是迭代器的增强) for (String s : k1) { System.out.println(s); } System.out.println("-------------"); //普通for 略(有索引才能用!比如说List) //方法四 k1.forEach(new Consumer<String>() {//接口 interface Consumer<T> @Override public void accept(String s) { System.out.println(s); } }); System.out.println("-------------");//简化 k1.forEach(s -> System.out.println(s));
List
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public static void main(String[] args) { // 1、创建一个队列。 LinkedList<String> queue = new LinkedList<>(); // 入队 queue.addLast("第1号人"); queue.addLast("第2号人"); queue.addLast("第3号人"); queue.addLast("第4号人"); System.out.println(queue); // 出队 System.out.println(queue.removeFirst()); System.out.println(queue.removeFirst()); System.out.println(queue.removeFirst()); System.out.println(queue); System.out.println("--------------------------------------------------"); // 2、创建一个栈对象。 LinkedList<String> stack = new LinkedList<>(); // 压栈(push)//源码就是addFirst stack.push("第1颗子弹"); stack.push("第2颗子弹"); stack.push("第3颗子弹"); stack.push("第4颗子弹"); System.out.println(stack); // 出栈(pop)//源码就是removeFirst System.out.println(stack.pop()); System.out.println(stack.pop()); System.out.println(stack); }
适用场景:1.设计队列(FIFO)2设计栈(FILO)
Set HashSet:无序不重复无索引
HashSet底层原理:哈希表=数组+链表(+红黑树) 哈希值对16求余,位置若为空则存入;位置若不为空,调用equals方法,若不等才存入,否则不存入
LinkedHashSet底层原理:数组+链表+红黑树(每个元素增加了双链表机制记住前后元素的位置,因此有序) TreeSet底层原理:红黑树(按照大小默认升序,适用于包装类和字符串) 若数据类型为自定义类型时需要自己指定排序规则:)set=new TreeSet<>(new Comparator() {注:如果两种方法都使用了那按照第二种有参构造器里面的规则来。
并发修改异常 不能用增强for循环!
用for循环 要么删除后马上i–,要么倒着遍历 1 2 3 4 5 6 7 for (int i=0;i< k1.size();i++) { if(k1.get(i).contains("6")){ k1.remove(i); i--; } } System.out.println(k1);
用迭代器1 2 3 4 5 6 7 Iterator<String> it = k1.iterator(); while (it.hasNext()) {//询问当前位置是否存在元素 if(it.next().contains("7")){ it.remove(); } } System.out.println(k1);
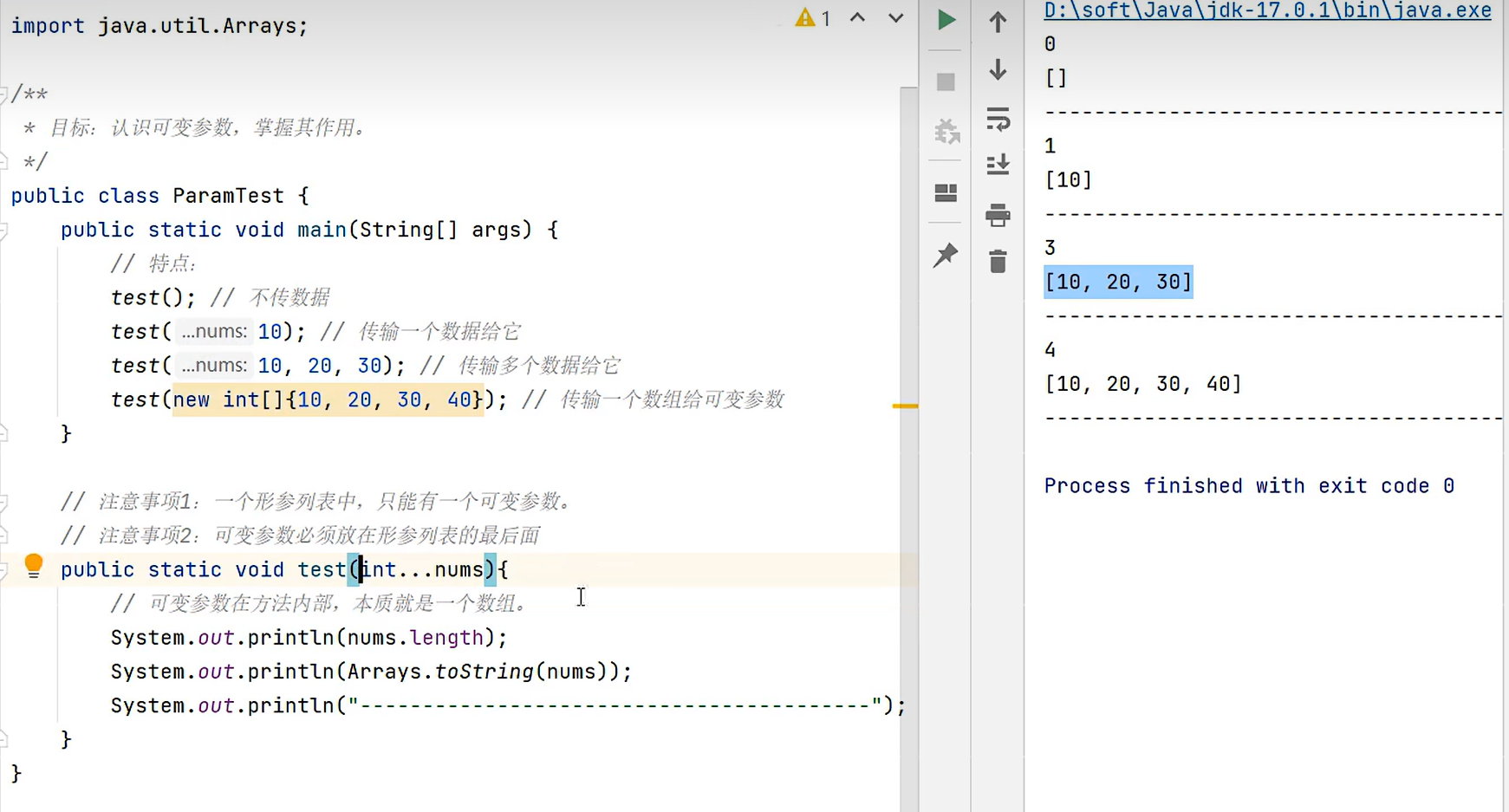
可变参数
Collections工具类
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 public static void main(String[] args) { // 1、public static <T> boolean addAll(Collection<? super T> c, T...elements):为集合批量添加数据 List<String> names = new ArrayList<>(); Collections.addAll(names, "张三", "王五", "李四", "张麻子"); System.out.println(names); // 2、public static void shuffle(List<?> list):打乱List集合中的元素顺序。 Collections.shuffle(names); System.out.println(names); // 3、 public static <T> void sort(List<T> list):对List集合中的元素进行升序排序。 List<Integer> list = new ArrayList<>(); list.add(3); list.add(5); list.add(2); Collections.sort(list); System.out.println(list); List<Student> students = new ArrayList<>(); students.add(new Student("蜘蛛精",23, 169.7)); students.add(new Student("紫霞",22, 169.8)); students.add(new Student("紫霞",22, 169.8)); students.add(new Student("至尊宝",26, 165.5)); // Collections.sort(students);//前提是自定义类已经实现了Comparable<student>接口 // System.out.println(students); // 4、public static <T> void sort(List<T> list, Comparator<? super T> c): 对List集合中元素,按照比较器对象指定的规则进行排序 Collections.sort(students, new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { return Double.compare(o1.getHeight(), o2.getHeight()); } }); System.out.println(students); }
Collection业务场景分析
Map(键值对集合) Map引入 业务场景:存储一一对应的数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 public static void main(String[] args) { // 1.添加元素: 无序,不重复,无索引。 Map<String, Integer> map = new HashMap<>(); map.put("手表", 100); map.put("手表", 220); map.put("手机", 2); map.put("Java", 2); map.put(null, null); System.out.println(map); // map = {null=null, 手表=220, Java=2, 手机=2} // 2.public int size():获取集合的大小 System.out.println(map.size()); // 3、public void clear():清空集合 //map.clear(); //System.out.println(map); // 4.public boolean isEmpty(): 判断集合是否为空,为空返回true ,反之! System.out.println(map.isEmpty()); // 5.public V get(Object key):根据键获取对应值 int v1 = map.get("手表"); System.out.println(v1); System.out.println(map.get("手机")); // 2 System.out.println(map.get("张三")); // null // 6. public V remove(Object key):根据键删除整个元素(删除键会返回键的值) System.out.println(map.remove("手表")); System.out.println(map); // 7.public boolean containsKey(Object key): 判断是否包含某个键 ,包含返回true ,反之 System.out.println(map.containsKey("手表")); // false System.out.println(map.containsKey("手机")); // true System.out.println(map.containsKey("java")); // false System.out.println(map.containsKey("Java")); // true // 8.public boolean containsValue(Object value): 判断是否包含某个值。 System.out.println(map.containsValue(2)); // true System.out.println(map.containsValue("2")); // false // 9.public Set<K> keySet(): 获取Map集合的全部键。 Set<String> keys = map.keySet(); System.out.println(keys); // 10.public Collection<V> values(); 获取Map集合的全部值。 Collection<Integer> values = map.values(); System.out.println(values); // 11.把其他Map集合的数据倒入到自己集合中来。(拓展) Map<String, Integer> map1 = new HashMap<>(); map1.put("java1", 10); map1.put("java2", 20); Map<String, Integer> map2 = new HashMap<>(); map2.put("java3", 10); map2.put("java2", 222); map1.putAll(map2); // putAll:把map2集合中的元素全部倒入一份到map1集合中去。 System.out.println(map1); System.out.println(map2); }
Map遍历 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 public static void main(String[] args) { Map<String,Integer>map1=new HashMap<>(); map1.put("蜘蛛精",187); map1.put("地藏",186); /* 方法一 键找值 */ Set<String>set= map1.keySet(); set.forEach(new Consumer<String>() { @Override public void accept(String s) { int value= map1.get(s); System.out.println(s+"----->"+value); } }); System.out.println("--------------------"); /* 方法二 键值对 */ Set<Map.Entry<String, Integer>> entries = map1.entrySet(); for (Map.Entry<String, Integer> entry : entries) { String key = entry.getKey(); Integer value = entry.getValue(); System.out.println(key+"---->"+value);//遍历键值对 } System.out.println("--------------"); /* 方法三:Lambda表达式 */ map1.forEach(new BiConsumer<String, Integer>() { @Override public void accept(String s, Integer integer) { System.out.println(s+"---->"+integer); } }); }
集合嵌套 举个例子
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 /* 需求 要求在程序中记住如下省份和其对应的城市信息,记录成功后,要求可以查询出湖北省的城市信息。 江苏省 = 南京市,扬州市,苏州市,无锡市,常州市 湖北省 = 武汉市,孝感市,十堰市,宜昌市,鄂州市 河北省 = 石家庄市,唐山市,邢台市,保定市,张家口 市 分析 定义一个Map集合,键用表示省份名称,值表示城市名称,注意:城市会有多个。 根据“湖北省”这个键获取对应的值展示即可。 */ public class MapTest { public static void main(String[] args) { /*一般集合的遍历 Map<String,String>map=new HashMap<>(); map.put("江苏省","南京市 "); map.put("湖北省","武汉市 "); map.put("河北省","石家庄市 "); Set<Map.Entry<String, String>> entries = map.entrySet(); entries.forEach(new Consumer<Map.Entry<String, String>>() { @Override public void accept(Map.Entry<String, String> stringStringEntry) { System.out.println(stringStringEntry.getKey()+"="+stringStringEntry.getValue()); } }); */ /* 集合的嵌套 */ Map<String, List<String>>map=new HashMap<>(); //List<String>list=new ArrayList<>(); List<String>city1=new ArrayList<>(); List<String>city2=new ArrayList<>(); List<String>city3=new ArrayList<>(); //city1.addAll(list); Collections.addAll(city1,"南京市","扬州市","苏州市","无锡市","常州市"); Collections.addAll(city2,"武汉市","孝感市","十堰市","宜昌市","鄂州市"); Collections.addAll(city3,"石家庄市","唐山市","邢台市","保定市","张家口"); map.put("江苏省",city1); map.put("湖北省",city2); map.put("河北省",city3); map.forEach(new BiConsumer<String, List<String>>() { @Override public void accept(String s, List<String> strings) { /* 法一 */ System.out.print(s+"="); int i=0; for (String string : strings) { System.out.print(string); if(i<strings.size()-1) { System.out.print(", "); } i++; } System.out.println(); /* 法二 */ System.out.print(s+"="); Iterator<String> iterator = strings.iterator(); while(iterator.hasNext()){ System.out.print(iterator.next()); if(iterator.hasNext()){ System.out.print(","); } } System.out.println(); } }); } }
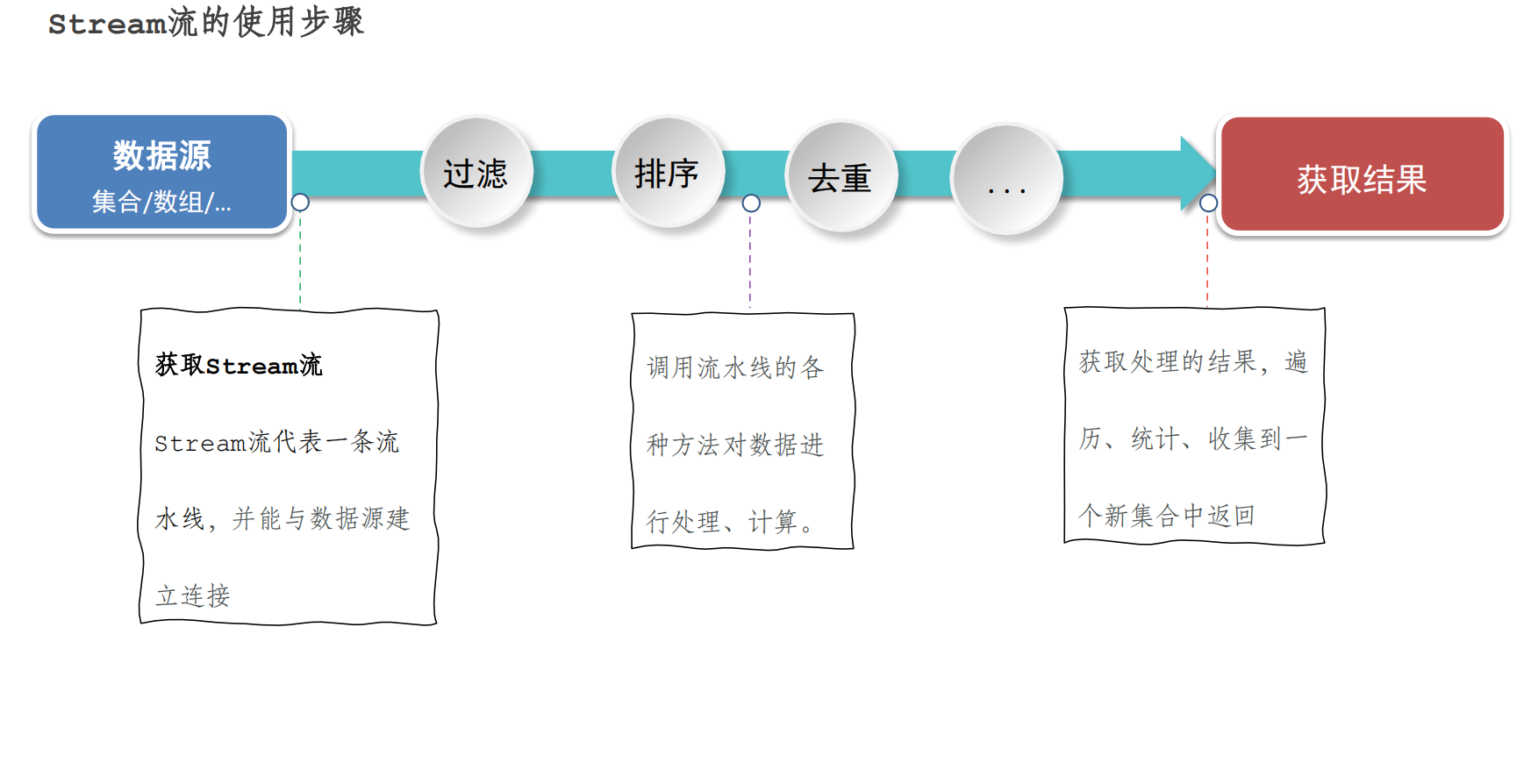
Stream流 什么是Stream?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 /*引入 /* 把集合中所有以“张”开头,且是3个字的元素存储到一个新的集合。 */ public class StreamTest1 { public static void main(String[] args) { List<String> list = new ArrayList<>(); List<String> list2 = new ArrayList<>(); // list.add("张无忌"); // list.add("周芷若"); // list.add("赵敏"); // list.add("张强"); // list.add("张三丰"); Collections.addAll(list,"张无忌","周芷若","赵敏","张强","张三丰"); System.out.println(list); for (String s : list) { if(s.startsWith("张")&&s.length()==3){ list2.add(s); } } //System.out.println(list2); //法二 用stream流来处理 //List<String> z = list.stream().filter(s -> s.startsWith("张") && s.length() == 3).collect(Collectors.toList()); //也可链式编程 List<String> z = list.stream().filter(s -> s.startsWith("张") ).filter(a->a.length()==3).collect(Collectors.toList()); System.out.println(z); } }
获取Stream流
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 public class StreamTest2 { public static void main(String[] args) { // 1、如何获取List集合的Stream流? List<String> names = new ArrayList<>(); Collections.addAll(names, "张三丰","张无忌","周芷若","赵敏","张强"); Stream<String> stream = names.stream(); // 2、如何获取Set集合的Stream流? Set<String> set = new HashSet<>(); Collections.addAll(set, "刘德华","张曼玉","蜘蛛精","马德","德玛西亚"); Stream<String> stream1 = set.stream(); stream1.filter(s -> s.contains("德")).forEach(s -> System.out.println(s)); // 3、如何获取Map集合的Stream流? Map<String, Double> map = new HashMap<>(); map.put("古力娜扎", 172.3); map.put("迪丽热巴", 168.3); map.put("马尔扎哈", 166.3); map.put("卡尔扎巴", 168.3); Set<String> keys = map.keySet(); Stream<String> ks = keys.stream(); Collection<Double> values = map.values(); Stream<Double> vs = values.stream(); Set<Map.Entry<String, Double>> entries = map.entrySet();//键值对 Stream<Map.Entry<String, Double>> kvs = entries.stream();//对键值对使用Stream流后遍历 kvs.filter(e -> e.getKey().contains("巴")) .forEach(e -> System.out.println(e.getKey()+ "-->" + e.getValue())); // 4、如何获取数组的Stream流? String[] names2 = {"张翠山", "东方不败", "唐大山", "独孤求败"}; Stream<String> s1 = Arrays.stream(names2); Stream<String> s2 = Stream.of(names2); } }
Stream提供的常用中间方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 import java.util.Objects; public class Student { private String name; private int age; private double height; @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return age == student.age && Double.compare(student.height, height) == 0 && Objects.equals(name, student.name); } @Override public int hashCode() { return Objects.hash(name, age, height); } public Student() { } public Student(String name, int age, double height) { this.name = name; this.age = age; this.height = height; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } public double getHeight() { return height; } public void setHeight(double height) { this.height = height; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + ", height=" + height + '}'; } } public class StreamTest3 { public static void main(String[] args) { List<Double> scores = new ArrayList<>(); Collections.addAll(scores, 88.5, 100.0, 60.0, 99.0, 9.5, 99.6, 25.0); List<Student> students = new ArrayList<>(); Student s1 = new Student("蜘蛛精", 26, 172.5); Student s2 = new Student("蜘蛛精", 26, 172.5); Student s3 = new Student("紫霞", 23, 167.6); Student s4 = new Student("白晶晶", 25, 169.0); Student s5 = new Student("牛魔王", 35, 183.3); Student s6 = new Student("牛夫人", 34, 168.5); Collections.addAll(students, s1, s2, s3, s4, s5, s6); // 需求1:找出成绩大于等于60分的数据,并升序后,再输出。 scores.stream().filter(s -> s >= 60).sorted().forEach(s -> System.out.println(s)); System.out.println("----------------------------------------------------------------"); // 需求2:找出年龄大于等于23,且年龄小于等于30岁的学生,并按照年龄降序输出. students.stream().filter(s -> s.getAge() >= 23 && s.getAge() <= 30) .sorted((o1, o2) -> o2.getAge() - o1.getAge()) .forEach(s -> System.out.println(s)); System.out.println("----------------------------------------------------------------"); // 需求3:取出身高最高的前3名学生,并输出。 students.stream().sorted((o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight())) .limit(3).forEach(System.out::println); System.out.println("----------------------------------------------------------------"); // 需求4:取出身高倒数的2名学生,并输出。 s1 s2 s3 s4 s5 s6 students.stream().sorted((o1, o2) -> Double.compare(o2.getHeight(), o1.getHeight())) .skip(students.size() - 2).forEach(System.out::println);//也可直接升序比较然后取前几个,此处介绍skip方法 System.out.println("----------------------------------------------------------------"); // 需求5:找出身高超过168的学生叫什么名字,要求去除重复的名字,再输出。 //students.stream().filter(s -> s.getHeight() > 168).map(s->s.getName()).distinct().forEach(System.out::println); //简化后: students.stream().filter(s -> s.getHeight() > 168).map(Student::getName).distinct().forEach(System.out::println); // distinct去重复,自定义类型的对象(若希望内容一样就认为重复,需要在自定义类中重写hashCode,equals,若未重写,认为地址不同就不算重复) students.stream().filter(s -> s.getHeight() > 168).distinct().forEach(System.out::println); System.out.println("----------------------------------------------------------------"); //需求6:合并两个流 Stream<String> st1 = Stream.of("张三", "李四"); Stream<String> st2 = Stream.of("张三2", "李四2", "王五"); Stream<String> allSt = Stream.concat(st1, st2); allSt.forEach(System.out::println); } }
面试常见问题:为什么重写了equals()还要重写hashcode():
Stream提供的常用终结方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class StreamTest4 { public static void main(String[] args) { List<Student> students = new ArrayList<>(); Student s1 = new Student("蜘蛛精", 26, 172.5); Student s2 = new Student("蜘蛛精", 26, 172.5); Student s3 = new Student("紫霞", 23, 167.6); Student s4 = new Student("白晶晶", 25, 169.0); Student s5 = new Student("牛魔王", 35, 183.3); Student s6 = new Student("牛夫人", 34, 168.5); Collections.addAll(students, s1, s2, s3, s4, s5, s6); // 需求1:请计算出身高超过168的学生有几人。 long size = students.stream().filter(s -> s.getHeight() > 168).count(); System.out.println(size); // 需求2:请找出身高最高的学生对象,并输出。 //Optional<Student> max = students.stream().max((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight())); Student s = students.stream().max((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight())).get(); System.out.println(s); // 需求3:请找出身高最矮的学生对象,并输出。 Student ss = students.stream().min((o1, o2) -> Double.compare(o1.getHeight(), o2.getHeight())).get(); System.out.println(ss); // 需求4:请找出身高超过170的学生对象,并放到一个新集合中去返回。 // 流只能收集一次。stream has already been operated upon or closed // at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:229)以下注释掉的是错误写法 // Stream<Student> studentStream = students.stream().filter(a -> a.getHeight() > 170); // System.out.println(studentStream.collect(Collectors.toList())); // System.out.println(studentStream.collect(Collectors.toSet())); List<Student> students1 = students.stream().filter(a -> a.getHeight() > 170).collect(Collectors.toList()); Set<Student> students2 = students.stream().filter(a -> a.getHeight() > 170).collect(Collectors.toSet()); System.out.println(students1); System.out.println(students2); // 需求5:请找出身高超过170的学生对象,并把学生对象的名字和身高,存入到一个Map集合返回。 //转成Map集合要加distinct()去重! Map<String, Double> map = students.stream().filter(a -> a.getHeight() > 170) .distinct().collect(Collectors.toMap(a -> a.getName(), a -> a.getHeight())); System.out.println(map); // Object[] arr = students.stream().filter(a -> a.getHeight() > 170).toArray(); Student[] arr = students.stream().filter(a -> a.getHeight() > 170).toArray(len -> new Student[len]); System.out.println(Arrays.toString(arr)); } }
前面没复习到的IO流以及IO框架
前面没复习到的线程内容 第三种创建线程的方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 package ThreadLearning.ThreadLearn; import java.util.concurrent.Callable; public class Way3 implements Callable<String> { private int n; public Way3(){ } public Way3(int p){ this.n=p; } @Override public String call() throws Exception { int sum=0; for (int i = 0; i <this.n ; i++) { sum+=i; } //把sum转换为String类型 return ("从0累加至"+n+"所得值为"+Integer.valueOf(sum).toString()); } } public class Test2 { public static void main (String[] args)throws Exception { Callable<String>cal=new Way3(20); FutureTask<String>ft=new FutureTask<>(cal); new Thread(ft).start(); String rs=ft.get();//得到return的值 System.out.println(rs); } }
线程池 用户每发起一个请求,后台就需要创建一个新线程来处理,下次新任务来了肯定又要创建新线程处理的,而创建新线程的开销是很大的,并且请求过多时,肯定会产生大量的线程出来,这样会严重影响系统的性能。线程池就是一个可以复用线程的技术。
}
方式一:使用ExecutorService的实现类ThreadPoolExecutor自创建一个线程池对象。 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler) /* 参数一:corePoolSize : 指定线程池的核心线程的数量。 正式工:3 参数二:maximumPoolSize:指定线程池的最大线程数量。最大员工数:5 临时工:2 参数三:keepAliveTime :指定临时线程的存活时间。临时工空闲多久被开除 参数四:unit:指定临时线程存活的时间单位(秒、分、时、天) 枚举类 参数五:workQueue:指定线程池的任务队列。客人排队的地方 接口,常见实现类:ArrayBlockingQueue , LinkedBlockingQueue 参数六:threadFactory:指定线程池的线程工厂。负责招聘员工的 要么自己写匿名内部类,要么用Executors.defaultThreadFactory() 参数七:handler:指定线程池的任务拒绝策略(线程都在忙,任务队列也满了的时候,新任务来了该怎么处理)。 忙不过来咋办? 1. new ThreadPoolExecutor.AbortPolicy()//实现类,public static class AbortPolicy implements RejectedExecutionHandler { } //丢弃任务并抛出RejectedExecutionException异常,是默认的策略 2. new ThreadPoolExecutor.DiscardPolicy()// 丢弃任务,但是不抛出异常 这是不推荐的做法 3. new ThreadPoolExecutor.DiscardOldestPolicy()// 抛弃队列中等待最久的任务 然后把当前任务加入队列中 4. new ThreadPoolExecutor.CallerRunsPolicy()// 由主线程负责调用任务的run()方法从而绕过线程池直接执行 */
注意事项:核心线程都在忙,任务队列也满了,并且还可以创建临时线程 ,此时才会创建临时线程。核心线程和临时线程都在忙,任务队列也满了,新的任务过来 的时候才会开始拒绝任务。
处理Runnable任务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 public static void main(String[] args) { ExecutorService ex=new ThreadPoolExecutor(3,5,8, TimeUnit.SECONDS, new ArrayBlockingQueue<>(4), Executors.defaultThreadFactory(), new ThreadPoolExecutor.CallerRunsPolicy());//实现类 /* * 线程池用Runnable方法 */ Runnable run=new MyRunnable(); //自动创建新线程 ex.execute(run); ex.execute(run); ex.execute(run); //如果核心线程执行完了,这里就复用核心线程,但是个数到了4个后还是要创建临时线程 eg.输出仍是:pool-1-thread-1在执行;若没完,则只能进任务队列排队,不输出 ex.execute(run); ex.execute(run); ex.execute(run); ex.execute(run); //开始创造临时线程 ex.execute(run); ex.execute(run); ex.execute(run);//临时队列满了,默认的拒绝策略会报异常 //其他还有不报异常或者老板亲自对接 ex.shutdown();//等全部任务执行完毕后,再关闭线程池 //ex.shutdownNow();//立刻关闭线程池,停止正在执行的任务,并返回队列中未执行的任务 }
处理Callable任务 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public static void main(String[] args) throws ExecutionException, InterruptedException { ExecutorService ex=new ThreadPoolExecutor(3,5,8, TimeUnit.SECONDS, new ArrayBlockingQueue<>(4), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy());//实现类 /* * 线程池用Callable方法 */ Future<String> ft1=ex.submit(new Mycallable(5)); Future<String> ft2=ex.submit(new Mycallable(5)); Future<String> ft3=ex.submit(new Mycallable(5)); Future<String> ft4=ex.submit(new Mycallable(5));//FutureTask<V>相当于是Future<V>接口的实现类 System.out.println(ft1.get()); System.out.println(ft2.get()); System.out.println(ft3.get()); System.out.println(ft4.get()); }
方式二:使用Executors(线程池的工具类)调用方法返回不同特点的线程池对象。
1 2 3 4 5 6 查看源码: public static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }//固定线程数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static void main(String[] args) throws ExecutionException, InterruptedException { ExecutorService ex= Executors.newFixedThreadPool(33); /* ctrl+alt+delete:任务管理器中查看cpu核数 计算密集型的任务:核心线程数量=CPU的核数+1; IO密集型的任务:核心线程数量=CPU的核数*2; */ Future<String> ft1=ex.submit(new Mycallable(5)); Future<String> ft2=ex.submit(new Mycallable(5)); Future<String> ft3=ex.submit(new Mycallable(5)); Future<String> ft4=ex.submit(new Mycallable(5)); System.out.println(ft1.get()); System.out.println(ft2.get()); System.out.println(ft3.get()); System.out.println(ft4.get()); }
注意事项:
特殊文件以及日志技术 特殊文件:
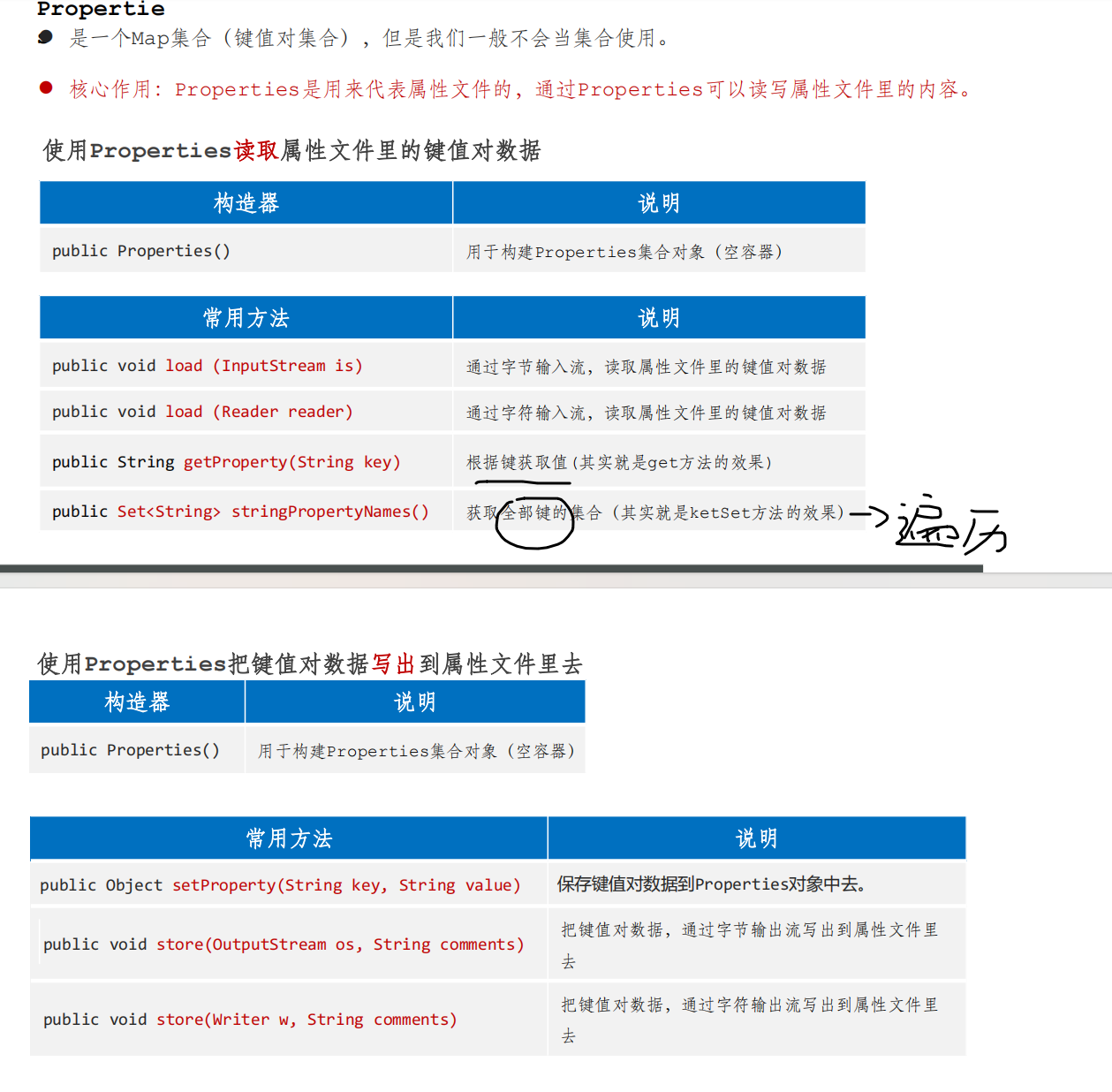
特殊文件 Properties
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 //读 public class PropertiesRead1 { /* users.properties原内容如下 #改好了 #Wed Jan 29 18:15:13 CST 2025 admin=123456 张无忌=minmin 周芷若=ji 赵敏=33 */ public static void main(String[] args) throws IOException { Properties pre=new Properties();//空容器 System.out.println(pre); pre.load(new FileReader("src/File/SpecialFile/users.properties")); System.out.println(pre); //System.out.println(pre.getProperty("张无忌")); Set<String> strings = pre.stringPropertyNames();//获取全部键 for (String string : strings) { System.out.println(string+"->"+pre.getProperty(string)); }//遍历全部键值对 System.out.println("----------"); Set<Map.Entry<Object, Object>> entries = pre.entrySet(); for (Map.Entry<Object, Object> entry : entries) { System.out.println(entry.getKey()+"->"+entry.getValue()); } System.out.println("----------"); pre.forEach(new BiConsumer<Object, Object>() { @Override public void accept(Object o, Object o2) { System.out.println(o+"->"+o2); } }); } }
1 2 3 4 5 6 7 8 //写 public class PropertiesWrite2 { public static void main(String[] args) throws IOException { Properties pro=new Properties(); pro.setProperty("几尔","aminos"); pro.store(new FileWriter("src/File/SpecialFile/users2.properties"),"go fuck yourself"); } }
1 2 3 4 5 6 7 8 9 10 11 //改 public class PropertiesExchange1 { public static void main(String[] args) throws IOException { Properties prop=new Properties(); prop.load(new FileReader("src/File/SpecialFile/users.properties")); if (prop.containsKey("赵敏")) {//不用遍历,直接用containsKey方法 prop.setProperty("赵敏","33"); } prop.store(new FileWriter("src/File/SpecialFile/users.properties"),"改好了"); } }
XML文件 XML的全称为(EXtensible Markup Language),是一种可扩展的标记语言。
如何写XML文件 XML的语法规则
文件后缀一般是是xml,文档声明必须是第一行 1 <?xml version="1.0" encoding="UTF-8" ?>
必须存在一个根标签,有且只能有一个
XML文件中可以定义注释信息:<!–- 注释内容 –>
标签必须成对出现,有开始,有结束标签:
必须能够正确的嵌套
XML中书写”<”、“&”等,可能会出现冲突,导致报错,此时可以用如下特殊字符替代。& ; & 和号&apos ; ‘ 单引号" ; “ 引号
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 <?xml version="1.0" encoding="UTF-8" ?> <!-- 注释:抬头申明必须第一行--> <users> <user id="1"> <name>张无忌</name> <sex>male</sex> <age>17</age> <![CDATA[超市里的马>我是逆蝶 ]]> </user> <people money="7"> <name>玉面手雷王</name> <iq>250</iq> </people> <user id="2"> <name>傻瓜</name> <sex>male</sex> <age>19</age> </user> </users>
如何利用程序读取XML文件中的数据 使用Dom4J解析出XML文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 public static void main(String[] args) throws DocumentException { SAXReader saxReader=new SAXReader(); Document read = saxReader.read("src/File/SpecialFile/newFirst.xml"); Element root = read.getRootElement();//根元素 System.out.println(root.getName());//users //List<Element> elements = root.elements(); List<Element> elements2 = root.elements("user");//指定拿的内容 for (Element element : elements2) { System.out.println(element.getName()); }//获取全部名为参数的一级子元素 System.out.println("------"); //法一 Element people = root.element("people");//拿到当前元素下的某个子元素 System.out.println(people.elementText("name"));//玉面手雷王//子元素.elementText("子元素属性名") //法二 相当于再遍历一层 Element name = people.element("name"); System.out.println(name.getText());//玉面手雷王 System.out.println("--------"); Element user = root.element("user");//如果下面有很多子元素,默认获取第一个 System.out.println(user.elementText("name"));//这里拿到的是张无忌 System.out.println(user.elementText("age"));//这里拿到的是17 Attribute id = user.attribute("id"); System.out.println(id.getName());//id //子标题属性名 System.out.println(id.getValue());//1 //子标题属性值 List<Attribute> attributes = user.attributes(); for (Attribute attribute : attributes) { System.out.println(attribute.getName()+"="+attribute.getValue()); }//类似键值对 id=1 System.out.println("-------"); }
如何利用程序把数据写出到XML文件中 建议直接把程序里的数据拼接成XML格式,然后用IO流写出去,不建议用dom4j做
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public static void main(String[] args) { StringBuilder sb=new StringBuilder(); sb.append("<?xml version=\"1.0\" encoding=\"UTF-8\" ?>\r\n"); sb.append("<user id=\"1\">"); sb.append("<name>").append("张无忌").append("</name>\n");//支持链式编程 sb.append("<sex>").append("male").append("</sex>\n"); sb.append("<age>").append("17").append("</age>\n"); sb.append("</user>\n"); try(BufferedWriter writer=new BufferedWriter(new FileWriter("src/File/SpecialFile/WriteOut.xml"));) { writer.write(sb.toString()); } catch (IOException e) { e.printStackTrace(); } }
补充知识:约束XML文件的编写[了解] 限制XML文件只能按照某种格式进行书写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 //导入dtd约束文档 <?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE 书架 SYSTEM "data.dtd"> <书架> <书> <书名>从入门到删库</书名> <作者>小猫</作者> <售价>很便宜</售价> </书> <书> <书名>从入门到删库</书名> <作者>小猫</作者> <售价>9.9</售价> </书> <书> <书名>从入门到删库</书名> <作者>小猫</作者> <售价>9.9</售价> </书> </书架>
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 //schema约束文档 <?xml version="1.0" encoding="UTF-8" ?> <schema xmlns="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.itcast.cn" //类似于包名 elementFormDefault="qualified" > <!-- targetNamespace:申明约束文档的地址(命名空间)--> <element name='书架'> <!-- 写子元素 --> <complexType> <!-- maxOccurs='unbounded': 书架下的子元素可以有任意多个!--> <sequence maxOccurs='unbounded'> <element name='书'> <!-- 写子元素 --> <complexType> <sequence> <element name='书名' type='string'/> <element name='作者' type='string'/> <element name='售价' type='double'/> </sequence> </complexType> </element> </sequence> </complexType> </element> </schema> //导入schema约束文档 <?xml version="1.0" encoding="UTF-8" ?> <书架 xmlns="http://www.itcast.cn" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.itcast.cn data.xsd"> <!-- xmlns="http://www.itcast.cn" 基本位置 xsi:schemaLocation="http://www.itcast.cn books02.xsd" 具体的位置 --> <书> <书名>从入门到删除</书名> <作者>dlei</作者> <售价>9.9</售价> </书> <书> <书名>从入门到删除</书名> <作者>dlei</作者> <售价>0.9</售价> </书> </书架>
日志技术 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public static void main(String[] args) { Scanner r=new Scanner(System.in); System.out.println("请输入r"); String number=r.next(); try { int result=Integer.valueOf(number); //int result=Integer.parseInt(number); System.out.println("整数值为"+result); } catch (NumberFormatException e) { e.printStackTrace(); System.out.println("输入有误"); } } /* 输出语句的弊端 日志会展示在控制台 不能更方便的将日志记录到其他的位置(文件,数据库) 想取消日志,需要修改源代码才可以完成 */
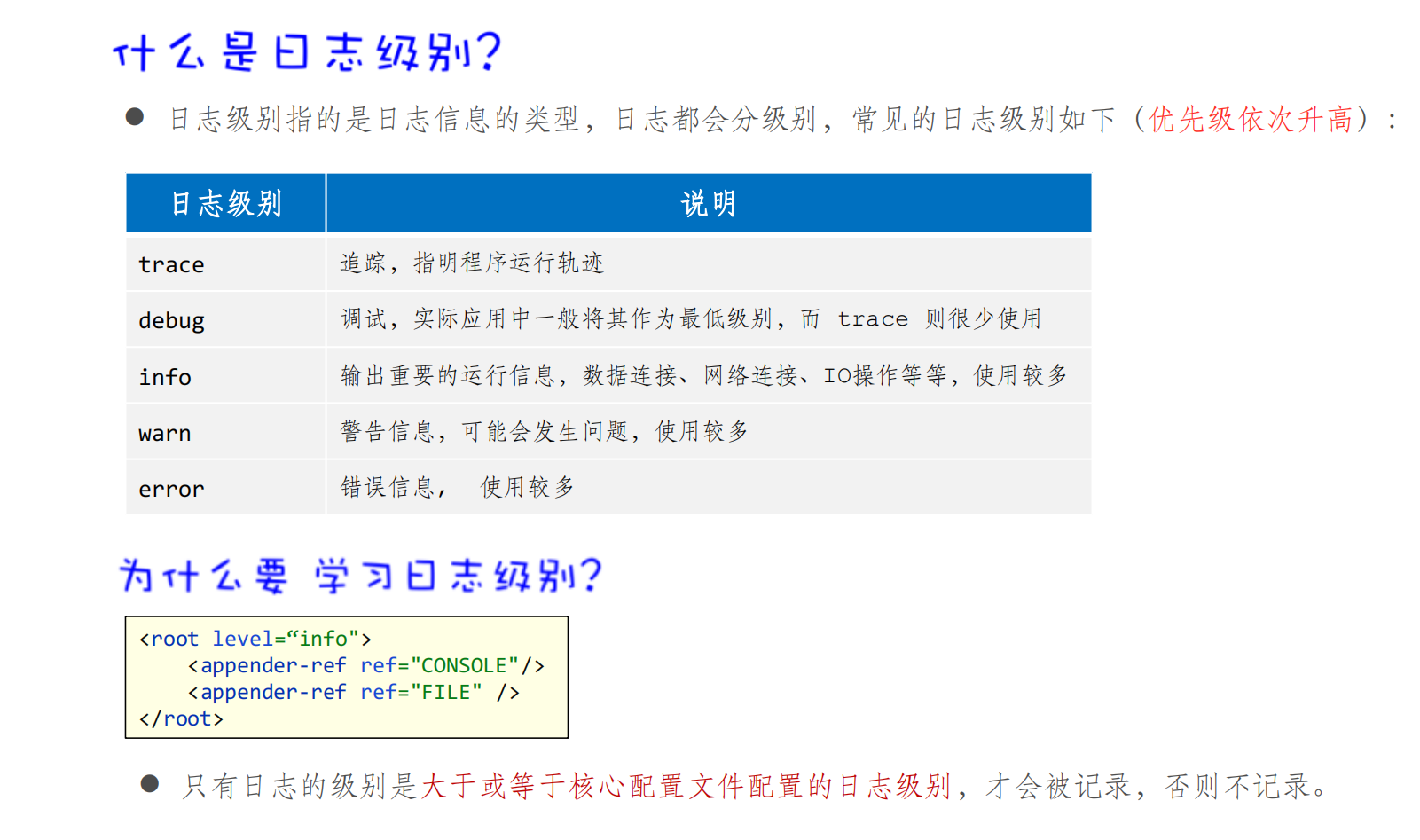
什么是日志?src目录下 。
1 2 3 4 public static final Logger LOGGER = LoggerFactory.getLogger(“类名"); LOGGER.debug("参数a的值为:"+a); LOGGER.info("chu法执行成功"); LOGGER.error("chu法执行失败");
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 <?xml version="1.0" encoding="UTF-8"?> <configuration> <!-- CONSOLE :表示当前的日志信息是可以输出到控制台的。 --> <appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender"> <!--输出流对象 默认 System.out 改为 System.err--> <target>System.out</target> <encoder> <!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度 %msg:日志消息,%n是换行符--> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%-5level] %c [%thread] : %msg%n</pattern> </encoder> </appender> <!-- File是输出的方向通向文件的 --> <appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"> <encoder> <pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern> <charset>utf-8</charset> </encoder> <!--日志输出路径--> <file>D:/log/itheima-data.log</file> <!--指定日志文件拆分和压缩规则--> <rollingPolicy class="ch.qos.logback.core.rolling.SizeAndTimeBasedRollingPolicy"> <!--通过指定压缩文件名称,来确定分割文件方式--> <fileNamePattern>D:/log/itheima-data-%i-%d{yyyy-MM-dd}-.log.gz</fileNamePattern> <!--文件拆分大小--> <maxFileSize>1MB</maxFileSize> </rollingPolicy> </appender> <!-- 1、控制日志的输出情况:如,开启日志,取消日志 --> <root level="debug"> <appender-ref ref="CONSOLE"/> <appender-ref ref="FILE" /> </root> </configuration>